So, I’ve been in Scottsdale, AZ for a work event these past few days. Solid event, good content, caught up with folks I haven’t seen in a while too. We wrapped with a dinner last night, and I’m headed home this morning. I’ve got a bit of time before my flight, so I figured I’d head down the road and get a bite at the Starbucks. Yeah, I know. I flew 2000 miles to go to Starbucks. But hey, it’s consistent, and I was feeling indecisive.
Outside view of the Waymo Car
I packed up my stuff so I can roll out to the airport when I’m done, leaving me with the need to get a mile up the road to the Starbucks. Not being jazzed about walking that while dragging my stuff, I caught a car. During the event, our AI Guru was talking about taking a fully autonomous car ride that week, so how could I resist, right? So, I grabbed the Waymo app and got registered.
Setting up the ride was about the same as Uber. Where are you going, confirm where you are right now, etc. The app said it would take 10 minutes for my ride to get there. My chariot, a highly modified Jaguar I-PACE EV SUV arrived in 8 – not bad! The car’s got a TON of cameras plastered all over it.
You unlock the doors with the Waymo app, which lets you pop the trunk as well. Dropped my stuff in the trunk, hopped in, got the intro briefing from the car, and off we went. It didn’t demand I buckle up until we were already moving and did so LOUDLY. Ok, whatever, safety first. Or at least third, right? You can control the music in the car with the touchscreen in the back, or with the Waymo app. I settled on Alternative and was treated to some Noah Kahan tunes.
If I’m honest, we got off to kind of a rocky start. There was a bunch of construction in the complex where the hotel was. I think the car got a little confused. Rather than go out the front exit, the way it entered, it took me out the side exit. It then proceeded to ignore the directions of one of the construction workers. No amount of her waving her arms telling the car to stop helped. Fortunately, we were creeping along at a blistering 5mph, and everyone was overall cool. The next worker up the way was a little bolder, standing in the middle of the street, directing the car. That time, the Waymo followed the worker’s directions, and off we went.
As far as driving style goes, for that early part of the ride, I’d describe it as similar to how my 17-year-old drove right after she got her license. Incredibly tentative about seemingly everything. She’s doing great now, by the way, and I’m sure Waymo will get there too. Once we got out on the main roads, the ride was really smooth. The Waymo drove courteously and safely. It got me to the Starbucks about a mile away in about 10 minutes. This was due mainly, of course, to the weird exit route.
As for dropping me off, well, that’s another matter. I punched in the address of the Starbucks, but the car sort of missed a little. The Waymo looked around for a spot to pull over and drop me off and settled on the far end of the parking lot. Again, whatever. Safety third, I guess.
The car was kind enough to remind me to take all my stuff with me, including the stuff in the trunk. It even automatically popped the trunk for me.
What’s the actual ride like? I grabbed a bit of video to show it off. Enjoy!
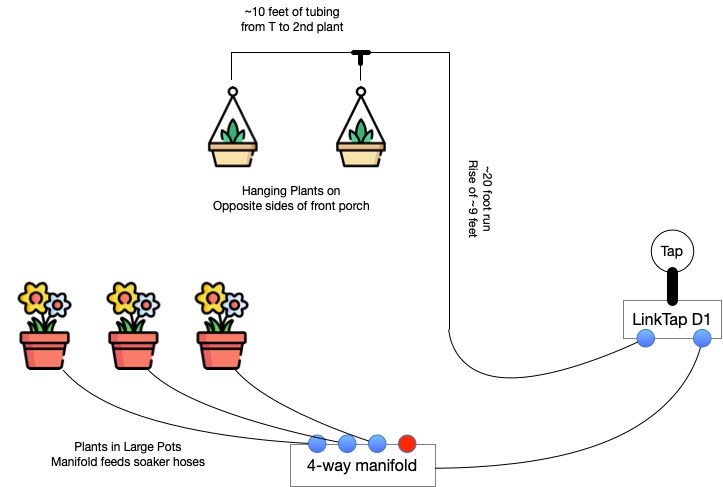
My wife LOVES to decorate with plants. She does it on the front porch, both with big pots with nice looking plants, as well as some hanging plants on either side of the porch. She does a great job of picking stuff out, planting, and styling the whole setup.
You know what she’s not always great at? Remembering to water those plants. NJ Summers being what they are (HOT!), it’s easy to forget for a day or two and end up with plants that are gasping for life, in desperate need of a drink. That’s where I come in. Having recently had surgery and not being able to execute the 2nd half of this plan on my own, thankfully I had a bit of help from a friend. I did manage to get the first part done before my surgery though.
So, for the front porch, she’s got 3 big pots with plants in them, and there’s the 2 hangers flanking the porch. I ended up deciding to split this into 2 watering zones, given how differently I’d be attacking each problem.
Feeding the whole thing: LinkTap D1
I searched and searched for the right solution. At first, I planned on doing this using Alexa Routines, as I use to automate most things. I first looked at the B-Hyve from Orbit. It didn’t expose Alexa actions, so I was stuck with mimicking Alexa voice commands in my routines. Not a big deal. The things that were a big deal to me? It didn’t stay connected reliably to our WiFi, despite being a few feet from an AP. That was one, and the second was when I called them to troubleshoot, they couldn’t understand the difference between Bluetooth and WiFi. I returned it.
I also looked at Rachio, but it was VERY hard to get ahold of at the time, so I moved on. Then I found LinkTap and went with them. I opted for their 2-zone D1 model, including the Gateway device.
LinkTap uses a Hub/Gateway model, which is of course, very common in the IOT world. The timer devices, called TapLinkers use Zigbee to talk back to the Gateway device. Setup was a snap. The app is absolutely hideous, but easy enough to work with. Setting up a schedule is pretty straight forward as well, so no complaints there.
My only complaint with LinkTap is their Alexa skill. When you invoke it to start a watering cycle, it always talks. So, when I set the routine up, every time it waters something, I’d hear “Got you. Now watering on XXXX.” Kind of annoying. Ultimately it caused me to junk the Alexa Routine for watering and break my own rule about home automation – I setup my watering routines in their app.
As a bonus, LinkTap offers a decent REST API. I haven’t done much of anything with it yet, but it’s good to know it’s there. LinkTap also has a line of valves designed for more “fixed” applications like sprinkler systems and such. Those are referred to as ValveLinkers.
Watering the Big Pots: Soaker Hoses
My first LinkTap zone is used for the big pots on the porch. I’m running a single leader hose from that tap out to one of those 4-way brass manifolds you can pickup at Home Depot. I’ve got 3 of the 4 taps on that open, each connected to a short feeder hose that runs to each pot. These hoses are made to custom lengths. How? I bought a 50-foot garden hose and a bunch of those repair ends for it. I cut the garden hose into the segments I needed and attached the appropriate ends. Those 3 hoses run to each of the 3 pots. In the pots themselves, I’ve got custom-length soaker hoses, built from one of those kits you can pickup in Home Depot. My wife bought one of those kits a couple of years ago, and it was just hanging out in the garage, waiting for this occasion.
Watering the Hanging Pots: Drip Irrigation
This was my first foray into drip irrigation, so I had a bit of read-up to do in order to figure out what I needed to buy to do the job right. Turns out that it was super easy to get it done. Water pressure is important, so I started with a pressure regulator, followed by an adapter to drop down from the usual 3/4″ garden hose fitting down to 1/4″ tubing.
As for tubing, I opted for polyethylene tubing, as it’s a bit more durable than PVC, though a bit less flexible than PVC. I felt the trade-off was worth it though. From the LinkTap to the porch itself, I used black tubing, held in place on the ground using those “staples” you use to hold landscape fabric down. When we reached the post we were going to run up to the top of the porch, we inserted an elbow and changed to white tubing, which we secured to the post using those U-shaped clips you see cable tv installers use to secure coax to baseboards. I had a bunch of those laying around, so nothing left to buy.
At the top of the porch, we used a T-fitting to split the runs to the 2 hanging plants, included a shut-off valve for each plant, and finally the drippers above each plant. You can see the shut-off valve and the dripper in the image just above!
I wouldn’t have been able to get this part done without the help of my good friend John, so thanks!
One of the great things about Junos is the automatic on-box configuration backup and instant rollback, right? Seriously, if you screwed things up in the recent past, you can easily recover by popping into configure mode, rolling back and committing your config. Plus, there’s amazing tools that prevent the walk/drive of shame like commit confirmed that go hand-in-hand. What I would have given all those years ago to have had tools like that in the bag when I was working on other platforms!
All that stuff aside, the on-box stuff is no substitute for long-term archival. Historical records of where system configurations have gone over the course of time is a big deal, operationally speaking. In Cisco-land, one of the old stand-by tools is RANCID. And yes, it works for Junos as well. But what if there was something better? What if there was something a bit more modern that better integrated with an up-to-date toolkit? Enter Oxidized.
Oxidized talks to a bunch of platform types, and outputs a bucket of different formats. You can do simple things like output the latest config as a text file, or you can output git repos either by groups of devices, or a single repo. You can even do things like have the tool perform HTTP POST operations to custom tools you’ve created. Backing up to the git repos for a second… Right along with that, you can have Oxidized push the local repo to a remote git repo as well, be that on the local network, or in the cloud somewhere! On top of all this, in addition to having its own nice web UI, Oxidized has really great integration with LibreNMS (which I use myself in my Homelab).
In the example I’m going to show, I’m going to use the Dockerized version of Oxidized to archive the configuration of my 3x EX2300-C VC at home. It will backup the config to a local git repo as well as push the config to a private GitHub repo. All communication over the network will be secured using SSH with ED25519 keys. No passwords are sent over the network at all! Ready? Let’s get started. I’m going to assume you’ve already got Docker and Docker Compose installed. If you don’t, get that done. There are more guides out there than I can count on that topic, so go ahead and locate one, and come back. 🙂
Ready? Ok, let’s go. I’m going to assume we’re building this on a Linux machine. If you’re not, as always “your mileage may vary”. Please feel free to comment below and contribute any adjustments you had to make to get things cooking on different platforms!
I’ll start by making a directory structure in my home directory where I’ll be working, then setting up my SSH key that the solution will use.
$ mkdir oxidized
$ cd oxidized
$ mkdir oxidized-volume
$ cd oxidized-volume
$ mkdir -p .config/oxidized
$ mkdir .ssh
$ chmod 700 .ssh
$ cd .ssh
$ ssh-keygen -t ed25519 -f id_ed25519 -C oxidized@blog.jasons.org
Generating public/private ed25519 key pair.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in id_ed25519
Your public key has been saved in id_ed25519.pub
The key fingerprint is:
SHA256:[redacted] oxidized@blog.jasons.org
The key's randomart image is:
+--[ED25519 256]--+
[ also redacted ]
+----[SHA256]-----+
$ cat id_ed25519.pub
ssh-ed25519 [redacted yet again] oxidized@blog.jasons.org
Next, we’ll create our docker-compose.yaml file in the top-level directory (at the same level as the oxidized-volume directory, above).
Next, setup the GitHub Repository. In my case, it’s going to be called jcostom/oxidized, and it will be private. In other words, I’ll be the only one who will be able to see or access the repo. Below, you’ll see the repo settings I chose.
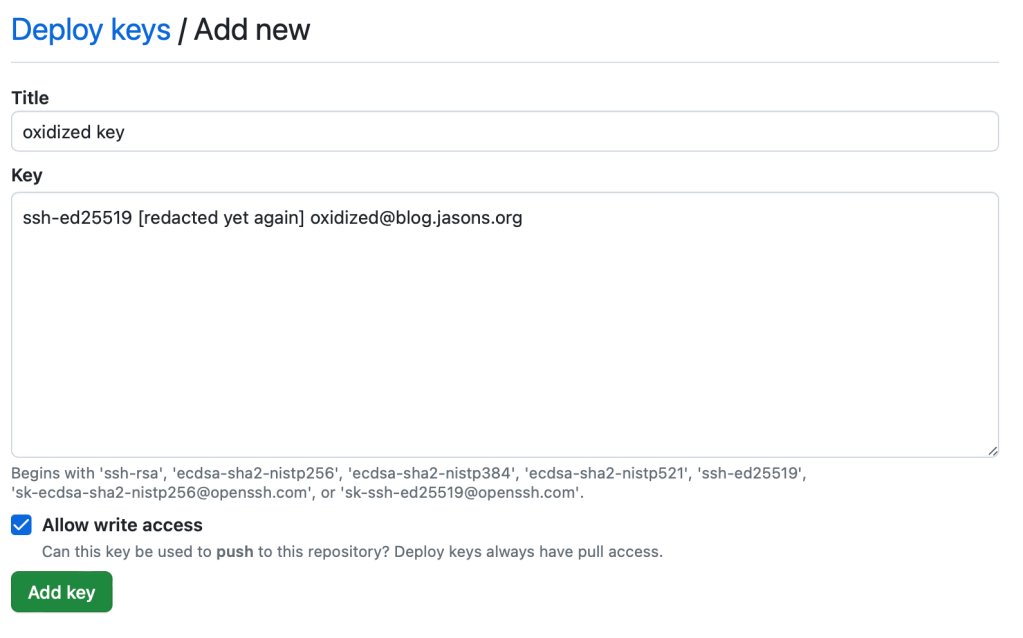
After you’ve created the repo, you’ll need to add your SSH key to the repo. Hit the Settings link on the top row, and on the left side, choose Deployment Keys. Add your SSH key.
Up next, let’s prepare our Junos devices to be backed up by Oxidized. To do this, we’re going to create a fairly restricted user class and a login that Oxidized will use. The authentication method will be… you guessed it! The SSH key we just generated before. So, the set of commands we’ll need to deploy to our Junos devices will look something like this:
set system login class oxidized permissions view-configuration
set system login class oxidized allow-commands "(show)|(set cli screen-length)|(set cli screen-width)"
set system login class oxidized deny-commands "(clear)|(file)|(file show)|(help)|(load)|(monitor)|(op)|(request)|(save)|(set)|(start)|(test)"
set system login class oxidized deny-configuration all
set system login user oxidized class oxidized
set system login user oxidized authentication ssh-ed25519 "ssh-ed25519 [redacted yet again] oxidized@blog.jasons.org"
Ok, so commit that config and you’re ready on the Junos side of things. Now we just need to finish up configuring Oxidized and we’ll be all done! Let’s create our Oxidized config. I won’t go through all the intricacies of this sample config, and yes, I’ll grant you that this is probably slightly more complex than it needs to be. That said, it’s ready to be expanded to accommodate additional system types really easily by adding additional groups and mappings. The 2 files, config and router.db both go in $DIR/oxidized-volume/.config/oxidized.
We’re just about ready to start things up! The Oxidized Docker container runs as an unprivileged user (hurray!), with both UID and GID 30000. So, we need to set the file ownership. You’ll need to change the ownership of the oxidized-volume and everything below it. The command is: sudo chown -R 30000:30000 oxidized-volume
Finally. We’re ready to start this thing up. There will be one final hiccup though. We’ll get through it. I promise. A final check – this is what your directory structure should look like… I’m going to assume you understand Unix file permissions. The permissions below are pretty basic – nothing crazy.
Ready to launch? Let’s Gooooooo! Get into that top level directory where your docker-compose.yaml file is and run the command docker-compose up. Provided you followed all the steps in order, and everything’s working, the oxidized/oxidized:latest image got pulled from DockerHub and launched per what’s in your Compose file. The first time you run things, you’re going to see an error that says Rugged::SshError: invalid or unknown remote ssh hostkey. That’s because the image doesn’t have the GitHub SSH key stored. We’re going to fix that though! Get to another terminal window and run this command: docker exec -it -u 30000:30000 oxidized /bin/bash
That’s going to drop you into a bash shell inside the Oxidized container. The first time out, we’re going to manually push to GitHub. Ready to fix it? Here goes.
cd ~/configs.git
git push --set-upstream origin master
You’ll get asked about accepting the SSH key, you’ll (naturally) say yes, the push will work, and you’re done. You can exit that shell with a Control+D. You can check the repo to see the push was successful. Here’s what mine looks like after that first push.
Guess what? You’re all done! You’ll probably want to hit Control+C in that Docker Compose session, and restart with a docker-compose up -d, which will start the services in the background, rather than the foreground. Every hour, Oxidized will poll your systems to see if the configs have changed. If so, the config will be backed up and pushed out to your private GitHub repo.
With the GitHub UI being as good as it is, you can probably see why I don’t bother with the Oxidized Web UI. Between it and the integration with LibreNMS, I simply have no real need for yet another way to consume the tool!
Over the past couple of years, I’ve built a number of tools that are delivered as Docker containers. Part of the workflow I’ve setup involves automatic container builds using GitHub Actions.
It works great – I commit to the main or dev branches and I get a new container version tagged as :latest or :dev, respectively. I create a new release version, and I get a new container version tagged as :version-number.
BUT, and there’s a but. There’s always a but, right? I’m talking about automatically updating the individual actions in my actions scripts to keep pace with new releases. Doing that manually is work for just 1 container. For a bunch? Forget it.
Dependabot has entered the chat.
What does Dependabot do? Its purpose in life is to look through your repo and keep versions of various bits up to date. Simple, right? Ok, like I said before, I’ve got a number of containers I maintain. Between my container build and old version cleanup scripts, I use 7 actions. Multiply that times 14 container repos, and that’s a total of 98 action instances to keep up to date. Hands up, who wants to do that by hand? Nope.
The other thing I’m using Dependabot for is to keep certain bits in my Dockerfiles up to date as well. The main one I look out for is the python:3.x slim images. All of this is configured using a YAML file that I drop in the repo as /.github/dependabot.yml . Here’s an example dependabot.yml file:
Around the middle of last year, I had to roll up to my company’s offices in New England for a couple of days of meetings. As I often do on such drives, I tune into a podcast or two between calls. During that drive, I caught a couple of episodes of the Politcology podcast. They ran a really great 2 part series about politically-motivated deepfakes (Episode 1 & Episode 2) which touched on other areas that are more relatable to our everyday lives.
They kicked off the first episode talking about the now-famous video that Jordan Peele and BuzzFeed created, showing President Obama saying things he never actually said. Here, check it out if you’ve never seen it:
This video was made a few years ago – back in 2018. If you really pay attention, you’ll notice that the voice isn’t quite right. It’s not perfectly synchronized with the facial movements, plus you can tell it’s not actually Obama’s voice. But, it’s good enough to convince a lot of folks, particularly those who aren’t well-informed, or just not paying attention.
Fast forward 5 years to 2023. How has the tech changed? Naturally, software has improved, plus there’s more compute power than ever. There are open-source tools out there to analyze existing media and leverage it to synthesize additional media. We’ve even seen attempts to use these tools in the past year. Look at the Russian invasion of Ukraine – I can recall at least 2 instances of faked videos used as propaganda tools. While better, one can still tell these videos are fakes.
The much greater danger we all face today is less about faked videos of world leaders and more about faked audio leveraged by criminals. Consider the voiceprint authentication systems we’re now seeing many companies deploy to verify our identities when we’re calling in for some sort of service. With just a few seconds of voice sample, the technology now exists to “put words in your mouth” – making synthetic recordings of you saying pretty much anything.
Ok, am I being an alarmist? Have I joined the tin-foil hat squad? I’ll point you to this recent article from TechCrunch about Microsoft’s VALL-E research project. Input 3 seconds of real speech audio from a person, and now you’ve got the power to produce whatever you’d like to hear, but in that person’s voice, with their diction, even with normal-sounding background noise. Now, imagine your bank deploys a voice-based authentication system like this. Some crook takes a few seconds of your voice, uses a tool like VALL-E, and whammo! Access to your accounts is granted.
Ok, so that’s audio – how close are we to average folks having access to manipulate someone’s likeness in a reliably, reproducible way? That’s today. In the past 10 minutes, I started off by going to Phil Wang’s This Person Does Not Exist site. There, I generated 2 face images, 1 male, 1 female. Next, I dropped these images into my iCloud Photo Library, got on my phone and used the FaceApp app to change the gender of each of these people. Check out the results below. “Originals” on the left, gender transformations on the right. Remember – none of these images are real people. They’re all generated and manipulated through software that uses AI.
Nifty, huh? Now, how about I take Mr. Fake Man and make him sing to us using the Facedance app?
It’s Corn!
Ok, I’ll be first in line to point out how not-perfect that video is. But, consider that I made it in about 10 seconds, using a free app on an iPhone 13 Pro. That tech’s only going to continue getting better at pretending.
So what to do? It seems clear that the present danger surrounds audio. I saw an interview the other day with a man who claimed to have been nearly scammed by a crook pretending to be one of his friends who needed a quick financial bailout. Had he not taken a moment to call the friend’s wife to check up about that voicemail first, he could have easily been scammed. My best advice? Verify before you send any money, even if it’s your family or best friend. Maybe even establish some sort of pre-arranged password or other way to authenticate the person on the other end.
Ok, so I built plugmon a while ago. It worked great. I loved it – super reliable, none of the fiddly nonsense I’ve had to work through with my vibration sensor-based dryer monitoring solution even. Sadly, the Etekcity smart plugs I used before, which used the (really nice) VeSync API no longer seem to be able to be purchased, easily at least.
So, what to do? If the code is to be useful long-term, we’ll need to change the platform to something that’s actually able to be purchased. Without question there’s no shortage of smart plugs available. So, what are desirable features that I’m after when looking for a different platform?
Naturally, I’m after some sort of way to easily talk to the plugs to read data. Of course, it also (should at least) goes without saying that we need a plug that offers the ability to monitor power use, as well as exposing some sort of API to allow use to get at that data without using the vendor’s app directly.
There’s a ton of options out there, but eventually, I landed with the Kasa (formerly TP-Link) plugs. Why? Two things really pushed them over the top. First of course was remote API-style access to the plug’s power monitoring data. But with the Kasa plugs one didn’t even need to go outside the home LAN to capture the data.
At the end of things, I kept the majority of code from jcostom/plugmon, grabbed a few bits of code from other projects I’ve worked on, and in about 30 minutes, the Washerbot was born.
It’s a shame that the VeSync plugs are now so difficult (impossible?) to come by. The API was reasonably easy to work with, and they weren’t terribly expensive either. I’m hopeful that TP-Link / Kasa Smart will be around for longer. I really like the “no outside connectivity” needed part of the python-kasa module as well.
Some may point out that there was a brief dust-up a couple of years ago with TP-Link, when they announced their intention to stop allowing local access to their devices, and you’d be right to do so. Fortunately, TP-Link was smart enough to take the not-so-subtle hints from the community, and walked that change back.
Without further ado, head over to GitHub and check out the new Washerbot code & container. Obviously, you’ll need one of the TP-Link plugs that provides energy use stats, like the KP115.
Many of you already use Let’s Encrypt certificates in various capacities to provide secure connectivity to applications and devices. Most of the time, these apps and devices automatically reach out, get certs issued, installed and everything just works. That’s cases like traefik, or certbot with apache/nginx, etc.
Then there are those “other” use cases you’ve got. Like say, a custom certificate for a Plex server, or maybe even something more exotic like a certificate for an HP printer. How do you take care of those in an automated, “hands-off” sort of way? How do you make it work so that you’re not having to set reminders for yourself to get in there and swap out certs manually every 3 months? Because you know what’s going to happen right? That reminder’s going to go off, you’re going snooze it for a couple of days, then you’ll tick that checkbox, saying, “yeah, I’ll do it after I get back from lunch” and then something happens and it never gets done. Next thing you know, the cert expires, and it becomes a pain in the rear at the worst possible moment.
That’s where deploy-hooks come into play. If you’ve got a script that can install the certificate, you can call that script right after the cert has been issued by specifying the --deploy-hook flag on the certbot renew command. Let’s look at an example of how we might add this to an existing certbot certificate that’s already setup for automatic renewal. Remember, automatic renewal and automatic installation are different things.
First, we’ll do a dry-run, then we’ll force the renewal. It’s really that easy. Check it:
Once this process is completed, the automatic renewal configuration for printer.mynetwork.net will include the deploy-hook /usr/local/sbin/pcert.sh. But, what does that really mean? Upon successful renewal, that script will execute, at which point, you’re (presumably) using the script to install the newly refreshed certificate. In this case, the script is unique to that particular certificate. It’s possible to have deploy-hooks that are executed fro EVERY cert as well, by dropping them in the /etc/letsencrypt/renewal-hooks/deploy directory.
For some examples, check out the ones I’m using. Especially interesting (to me at least) is the HP Printer script. That one took a bit of hackery to get working. I had to run the dev tools, and record the browser session a couple of times to get all the variable names straight, and so forth, but once I had it down, it was a snap. Now when the Let’s Encrypt cert updates, within a few seconds, I’ve got the latest cert installed and running on the printer!
[Any Amazon Links below are Non-Affiliate Links that just go to Amazon Smile]
So, if you think back a bit, you may recall that I was using a Pi 4 for my IoT project that monitored the dryer, shooting out Telegram group messages to the whole family when the dryer was done with the laundry.
Times being what they are, it’s pretty difficult to come by a new Raspberry Pi these days, as I’m sure many of you know. I needed the power of the Pi 4 for something else, at least on a temporary basis. Meanwhile, back at the ranch, a couple of months prior, I’d received a ping from the Micro Center about 45 minutes away informing me that they had a handful of Pi Zero 2 W’s on hand. Those little suckers are super hard to find, so I snapped up my max of 2, along with the GPU I’d been dying to lay hands on for the longest time. For those who care, I finally got an EVGA 3080. Pandemics and supply-chain constraint conditions suck, by the way, in case you were wondering my position on that issue.
So, having my Pi Zero 2 W in the drawer ready to roll, I unscrewed the box from the way that housed the Pi 4, fitted the sensor I had directly onto the Pi Zero 2 W, and scaled down from a 2-project-box solution down to 1 box. Sadly, it sucked. But, it wasn’t the hardware’s fault. In reality it was totally a self-inflicted condition.
I modified (slightly) the pins on the old 801s sensor I had, fitted it onto that new Pi Zero 2W (since it didn’t have any GPIO pin headers soldered on), and sort of Rube-Goldberged it together using 3M VHB tape inside the project box. Total hack job. I thought about using a bunch of hot glue, but then I thought better of it. Why not solder? Honestly? I suck at soldering. One of these days I’ll get around to getting good at it. But that’s not today.
It was wildly unstable. The sensor kept on moving, losing contact with the side of the GPIO holes, it was awful. I all but gave up. I had a brief flirtation with the Aqara Smart Hub and one of their Zigbee Vibration sensors, and believe me, when I say brief, I mean like 12 hours. It just wasn’t fit for the job.
My grand plan with that was to mimic what I was doing over on the washer – write some Python code and run it in a container to query an API somewhere in the cloud every X seconds to see if the thing was vibrating or not, then based on that, work out the state of the dryer to determine if the dryer had started or stopped and then act accordingly. But alas, since step 2 in this plan was a klunker, steps 3 through infinity? Yeah, those never happened.
So, back to the drawing board. I found that I couldn’t easily lay hands on a new 801s again, and the project for the Pi4 was now finished, so I had that back. I did find a new vibe sensor – the SW-420. 3 pins instead of 4, but it’s still a digital output that works fine with the Pi, and my existing code worked as-is, so who cares, right? Yeah, I classed the thing up quite a bit more this time too. This time, instead of shoving the Pi inside a project box that’s mounted on the wall running from the SD card, I opted to run in one of those snazzy Argon One M.2 SSD cases booting Ubuntu 22.04 from an M.2 SSD in the basement of the case. I’ve got that sitting on a lovely little shelf mounted just above and behind the dryer, with my 3 GPIO leads running out of the top of the case, directly into the small project box that’s attached to the front of the dryer, inside which is the sensor, which is stuck to the inside of the box using 3M VHB tape. The box itself is stuck to the dryer using VHB tape as well.
In the end, all’s well that ends well. I’ve had to do a good bit more tuning on the SW-420 sensor. It’s been a bit more fiddly than the old 801s was. That one was definitely a plug and play affair. This has required a bit of adjustment on the little potentiometer that’s built into the sensor. Not too bad though. I’ve invested probably a total of 15 minutes of time standing next to the dryer, staring at telemetry, while the dryer is running, or not. But in the end, it’s all working, and the notifications are happening once again.
Summer’s been absolutely nuts. Between work stuff, family stuff, running here and there, and of course, the odd project or two, I’ve been just plain stretched for time.
Stay tuned. I’ll be coming back around shortly. I’m working on some things. Preview?
Well, Remember how Logitech decided that the Harmony Remote, one of the best things ever to happen to the world of universal remotes was going to be taken out back and killed? Yeah, I was pretty mad about that too. So, I went looking for something else to solve some automation challenges with that. So, that’s coming.
What else? Tried to buy a Raspberry Pi lately? Heh. Yeah, me too. I decided to try a different fruit for a change. So far, so good. More on that later.
More still? There’s an update on that printer situation. The dryer too.
How about a Raspberry Pi-based network console server for my network equipment?
I, like many, hate DNS. I tolerate it. It’s there because, well, I need it. There’s just only so many IP addresses one can keep rattling around inside one’s head, right? So, it’s DNS.
For years, I ran the old standard, BIND under Linux here at home. My old BIND config did a local forward to dnscrypt-proxy, which ran bound to a port on localhost, and then in turn pushed traffic out to external DNS servers like Cloudflare’s 1.1.1.1 or IBM’s 9.9.9.9. I didn’t think my ISP was entitled to be able to snoop on what DNS lookups I was doing. They still aren’t entitled to those, so I didn’t want to lose that regardless of what I ended up doing.
Out in the real world, my domain’s DNS was hosted by DNS Made Easy. They’ve got a great product. It’s reliable, and it’s not insanely expensive. It’s not nothing, but we’re not talking hundreds a year either. I think it’s about $50 a year for more domains and queries than I could possibly ever use. But, like many old schoolers, they’ve lagged behind the times. Yes, they’ve got things like a nice API, and do support DNSSEC, but DNSSEC is only available in their super expensive plans that start at $1700+ a year. That’s just not happening. So, I started looking around.
I landed on Cloudflare. They’ve got a free tier that fits the bill for me. Plenty of record space, a nice API, dare I say, a nicer API even. DNSSEC included in that free tier at no cost even. How do you beat free? I was using a mish-mash of internal and external DNS with delegated subdomains for internal vs external sites as well. It was (again) complicated – and a pain in the rear.
So, I registered a new domain to use just for private use. I did that through Cloudflare as well. As a registrar, they were nice to work with too. They pass that through at cost. Nice and smooth setup. So, internal stuff now consists of names that are [host/app].site.domain.net. Traefik is setup using the Cloudflare dns-01 letsencrypt challenge to get certs issued to secure it all, and the connectivity, as discussed before in the other post is all by Tailscale. The apps are all deployed using Docker with Portainer. The stacks (ok, they’re just docker-compose files) in Portainer are all maintained in private GitHub repos. I’ll do a post on that in more detail soon.
Ok, so what did I do with the DNS at home? Did I just ditch the resolver in the house entirely? I did not. In the end I opted for dumping BIND after all these years and replacing it with Unbound. I had to do a bit of reading on it, but the configuration is quite a bit less complex, since I wasn’t configuring zone files any more. I was just setting up a small handful of bits like what interfaces did I want to listen to, what did I want my cache parameters to look like, and what did I want to do with DNS traffic for the outside world, which pretty much everything is? In my case, I wanted to forward it to something fast and secured. I was already crushing pretty hard on Cloudflare, so 1.1.1.1 and 1.0.0.1 were easy choices. I’m also using IBM’s 9.9.9.9 as well. All of those are forwarding out using DNS-over-TLS, and DoT, or sometimes DOT. It worked for me first try.
Then I grabbed the Ubuntu certbot snap and told it to grab a cert for dns.home.$(newdomain).net, which is attached to this moon. After I got the cert issued, it was a piece of cake to turn up both DNS over HTTPS and DNS over TLS, and DoH and DoT.
It was fairly easy to get DoH working on a Windows 11 PC. It was also super easy to craft an MDM-style config profile for DoT that works great on IOS and iPadOS devices. Microsoft has Apple beat cold in this department. Well, in the Apple wold, if you configure a profile for DoT (the only way you can get it in there) you’re stuck with it until you get rid of it – by uninstalling and reinstalling.
On Windows? It was as easy as setting your DNS servers to manual, then crack open a command prompt as Administrator and then (assuming your DNS server is 10.10.10.10)…
netsh dns add encryption 10.10.10.10 https://my.great.server/dns-query
Once you’ve done that, you’ll be able to choose from a list under where you punch in DNS settings in the network settings and turn on Encryption for your DNS connection. It’s working great!














You must be logged in to post a comment.